--- Compiling #TidyTuesday Information for 2023-04-11 ----
--- There are 2 files available ---
--- Starting Download ---
Downloading file 1 of 2: `egg-production.csv`
Downloading file 2 of 2: `cage-free-percentages.csv`
--- Download complete ---
eggproduction <- tuesdata[["egg-production"]][, 1:5] #remove source as it won't be helpful to uscagefreepercentages <-tuesdata[["cage-free-percentages"]][, 1:3]
Data Exploration and Cleaning
For the sake of this exercise, I’m going to be focusing on the eggproduction dataset. First I’m going to do some exploratory graphing to see what the general distributions look like. After looking, the structure of all the variables are as their supposed to be - dates as dates, numbers are numbers, etc.
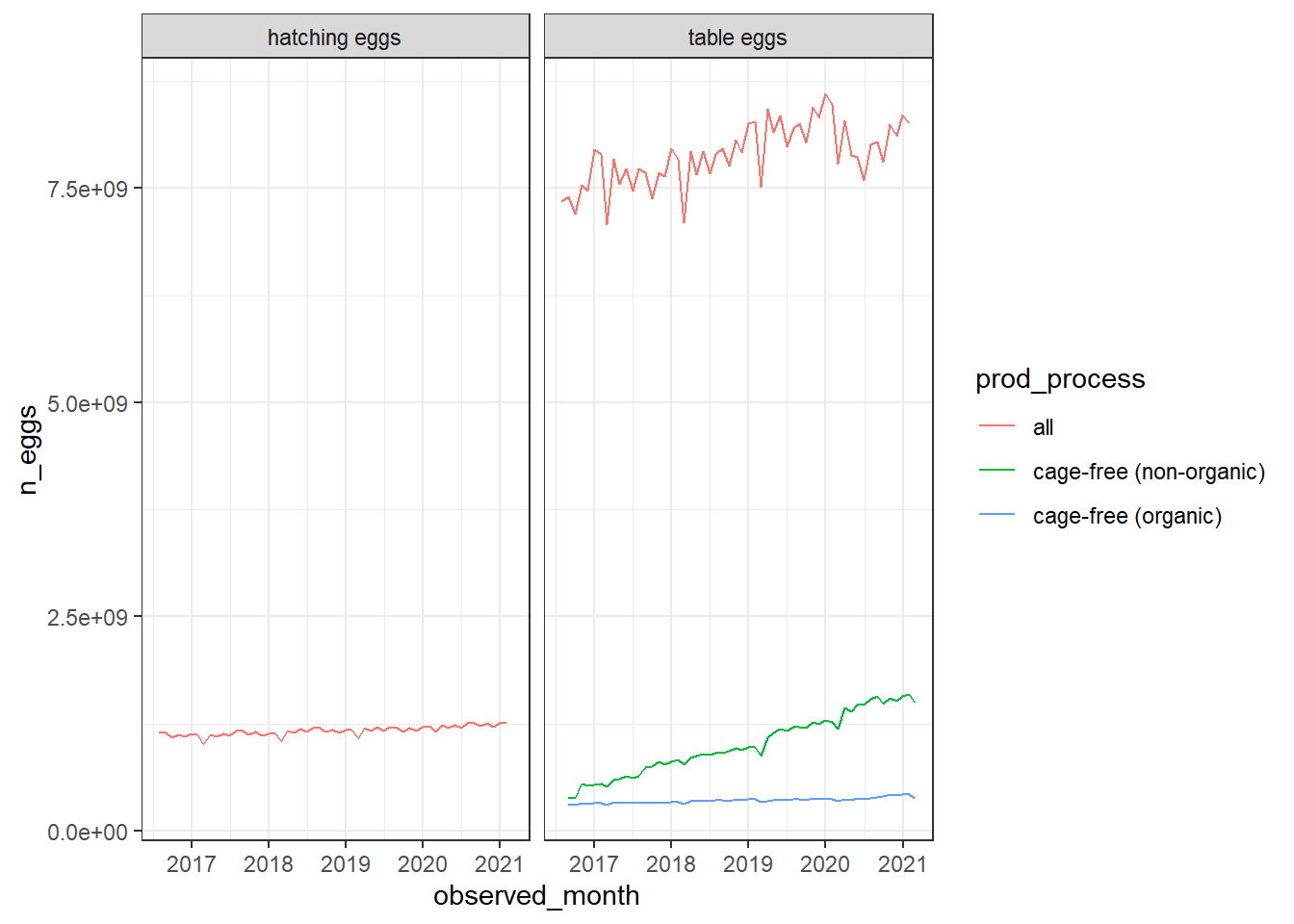
This is great! This graph tells us a lot. First, it shows the data is pretty clean as the data graphed with no problems. It tells us that table eggs are produced at a vastly greater rate than hatching eggs, and that there are no cage-free hatched eggs. We also see a rise in production of table eggs for cage-free (nonorganic) and the total trend.
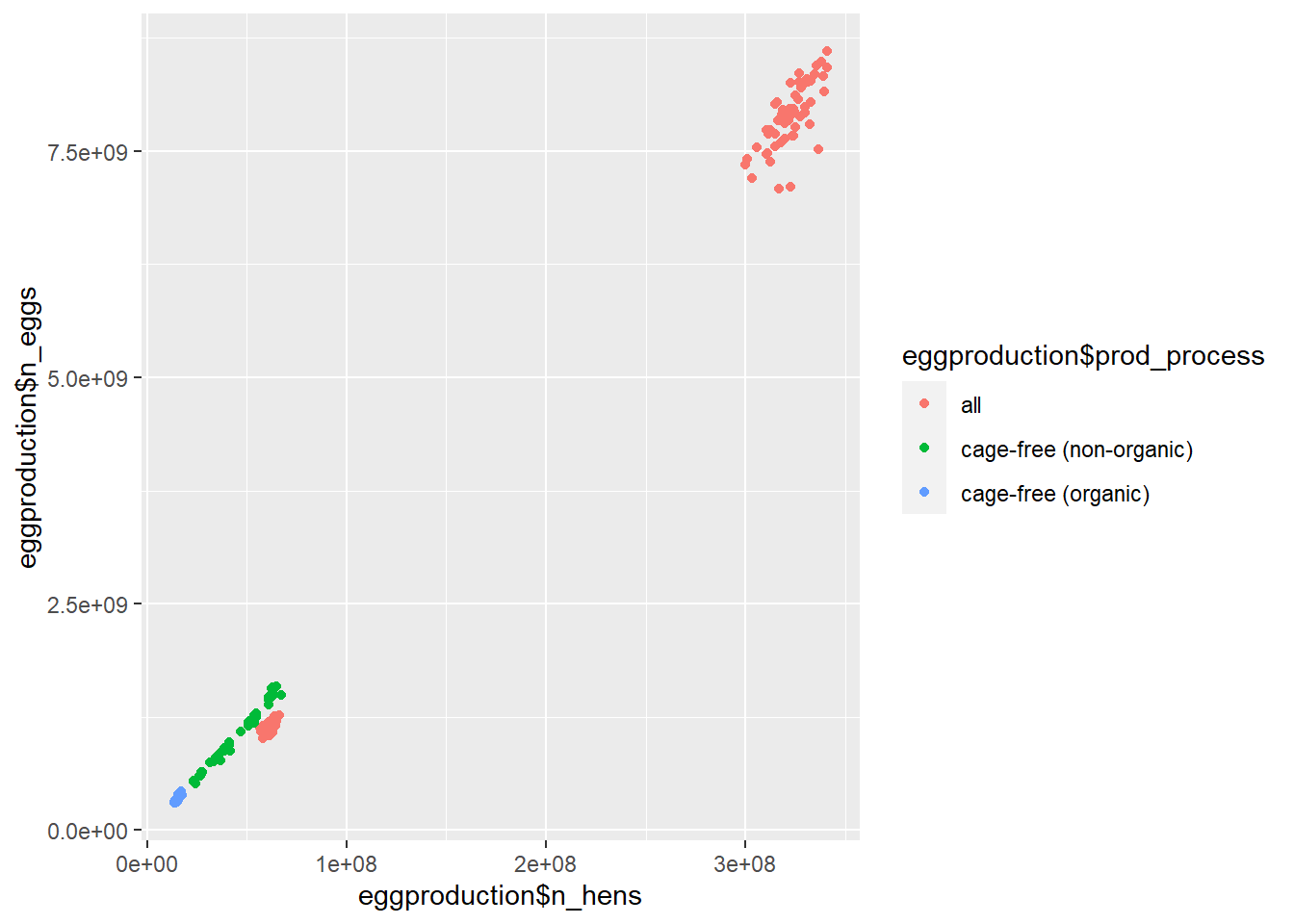
We see the differences in egg production by type of egg replicated in this scatter-plot, but we can also see the nearly straight correlation between the number of eggs and the number of hens across all groups. This doesn’t help us much in terms of creating a hypothesis about possible differences here.
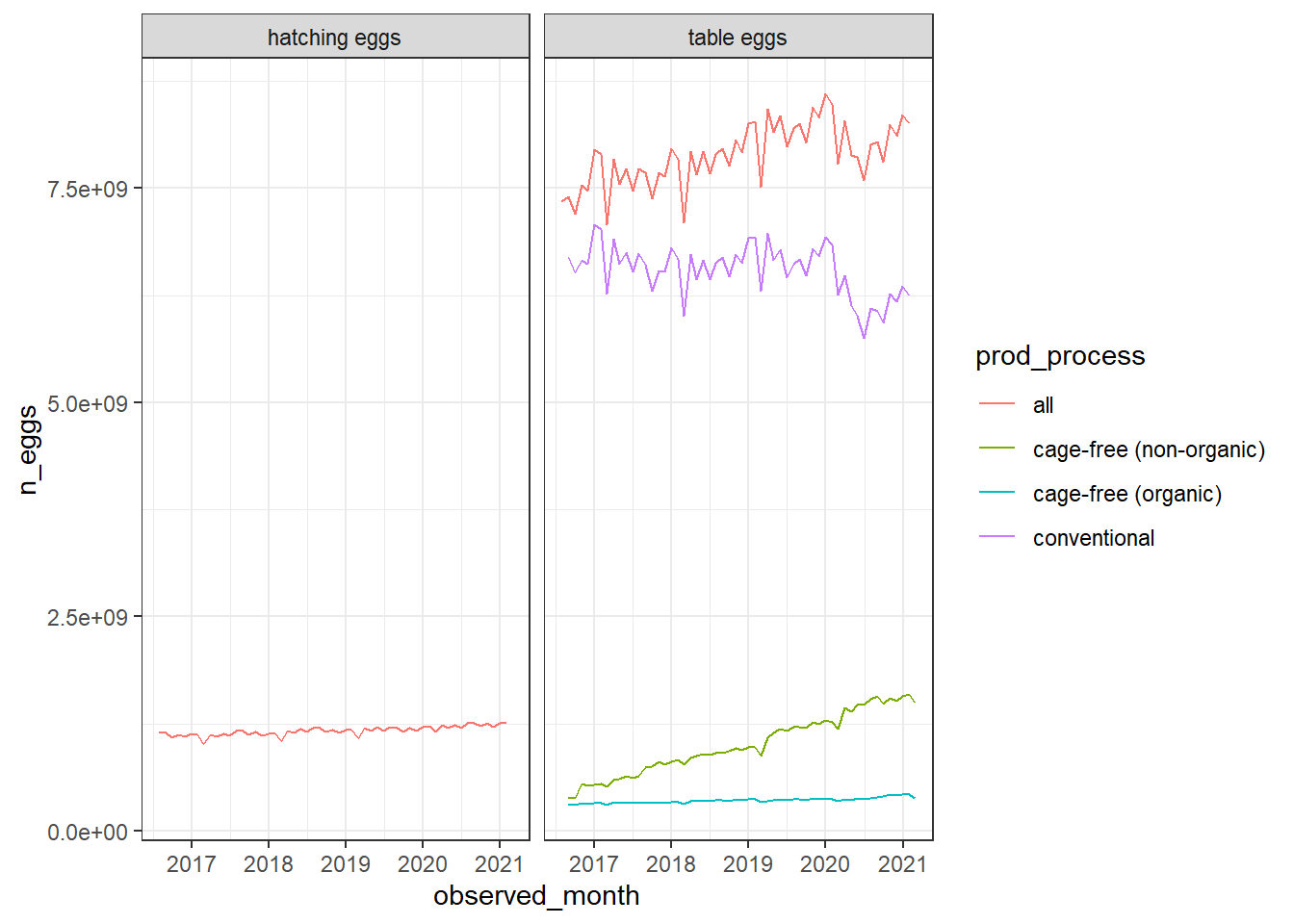
The only data cleaning I want to do off the bat is create another category rather than “all”, since this is a sum that includes cage-free and I want to see what the conventional housing distribution is alone.
Awesome! Now we can start looking into hypotheses and questions for our model.
Hypothesis Generation
While we have consistent information for trends related to years and within the number of eggs hatched per hen, I’m interested in seeing this data at the monthly level and within different production processes. To do this, I’m going to clean the data a bit further to focus on the table eggs since we have different production methods, elimininate the “all” option, and isolate the month the eggs were produced.
Based on the line graphs, it seems there dips in egg production around Feb/March each year. I predict that Feb/March has the greatest negative impact on egg production while early summer months (May/June) have the greatest positive impact on egg production. I’m using the production process as a strata in case this varies by process. Because of this, I am including the variable in the model.
For the lasso I’m changing up the workflow based on a resource a classmate recommended to me by one of the tidymodels creators. We’re going to see if I have better luck with these methods. Her explanations were very helpful, and hopefully her methods will work on my data!
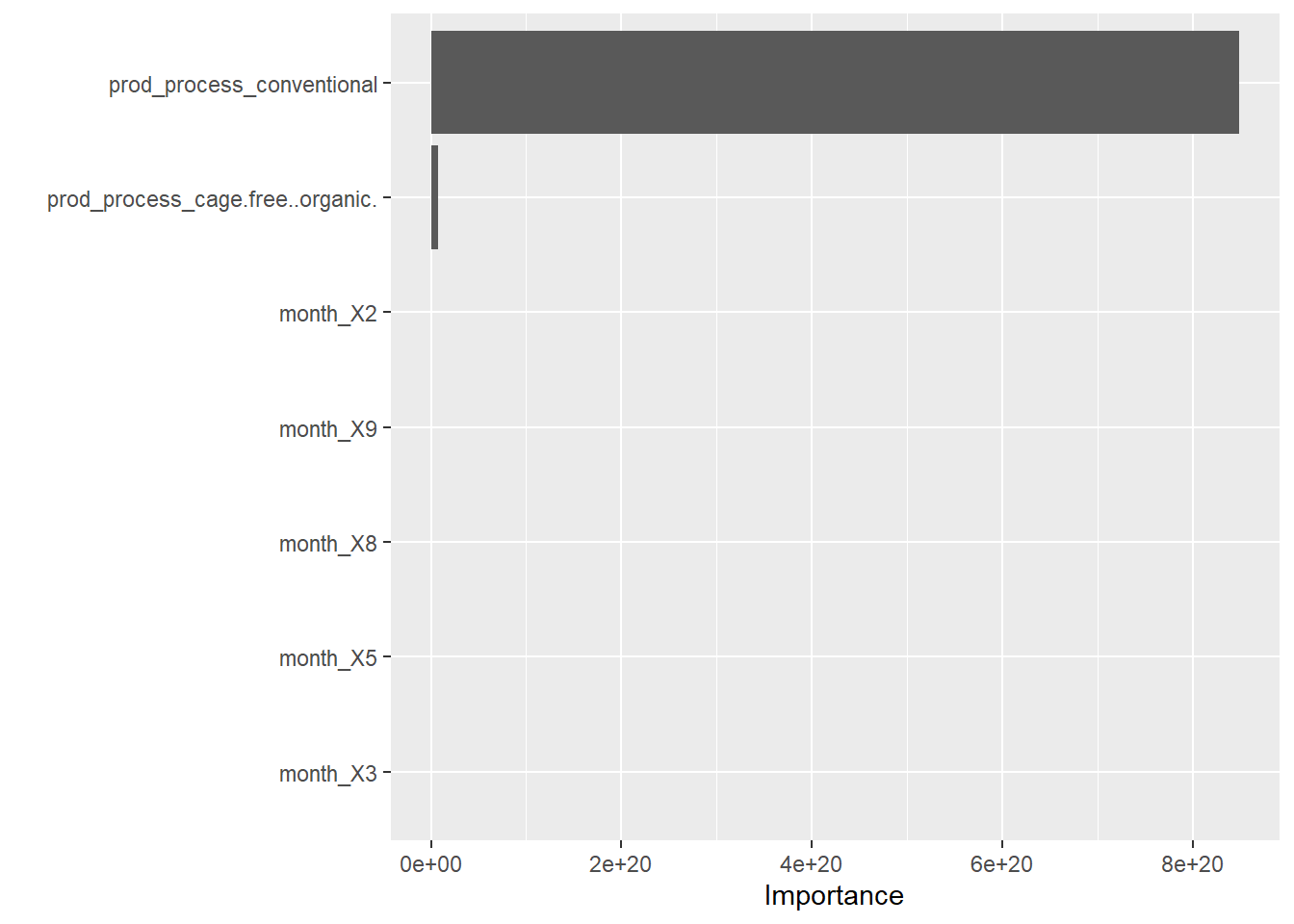
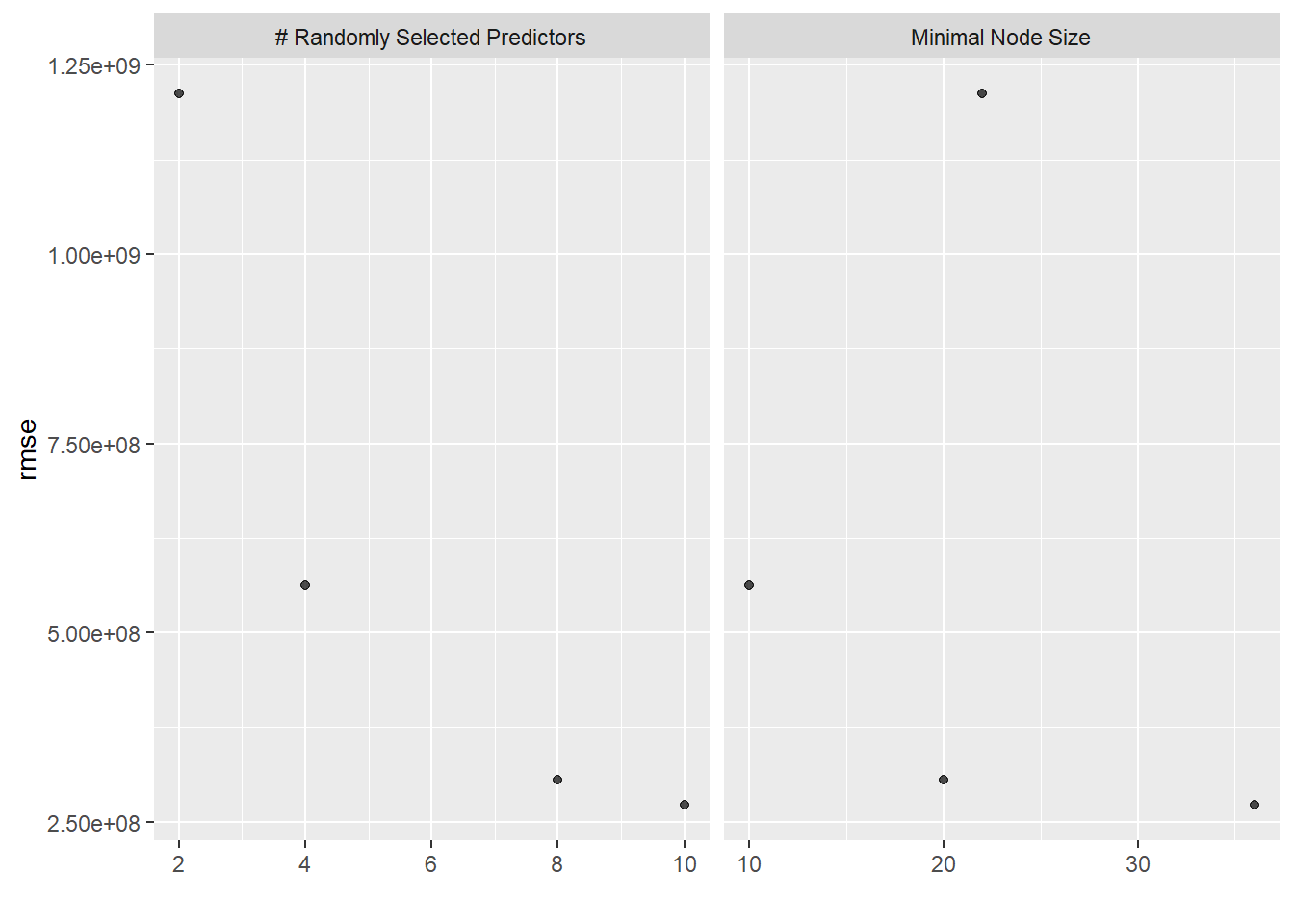
There are several obvious drawbacks to these methods. I was trying to determine the month with the largest impact on egg production, controlled for egg production type. However, the tidymodels framework did not allow for this or eliminating the variable to only include month. Therefore, since conventional production was such a large percentage of the eggs produced, it was often included in the model. This was especially evidenced in the decision tree. Therefore, this scored the most poorly of all the models since it could not discern any other variations within the data.
Next, and I think this is user error, is I’m not sure how to pull out the significant predictors for random forest models. I’m not sure if I’m overlooking a basic command or if this is so much of a “black box” model that we just have to take it at its word. For this reason, I would not choose to use a model.
Then, we have the null model. It’s great for averages, but does not give us good change over time, and its RMSE was insanely high for both the trained and tested data. But it’s an average, which can’t go too wrong, just not very powerful for answering questions about the data itself.
That leaves the LASSO model. I switched workflows to mirror one from a tidymodels creator, and it was very helpful and intuitive to what the steps in the code were doing. I’m not sure if these can be applied to other model types because by the end of this exercise workflows, parameters, and grids were swimming too much in my head to identify the exact differences in coding styles and apply it to the other model types.
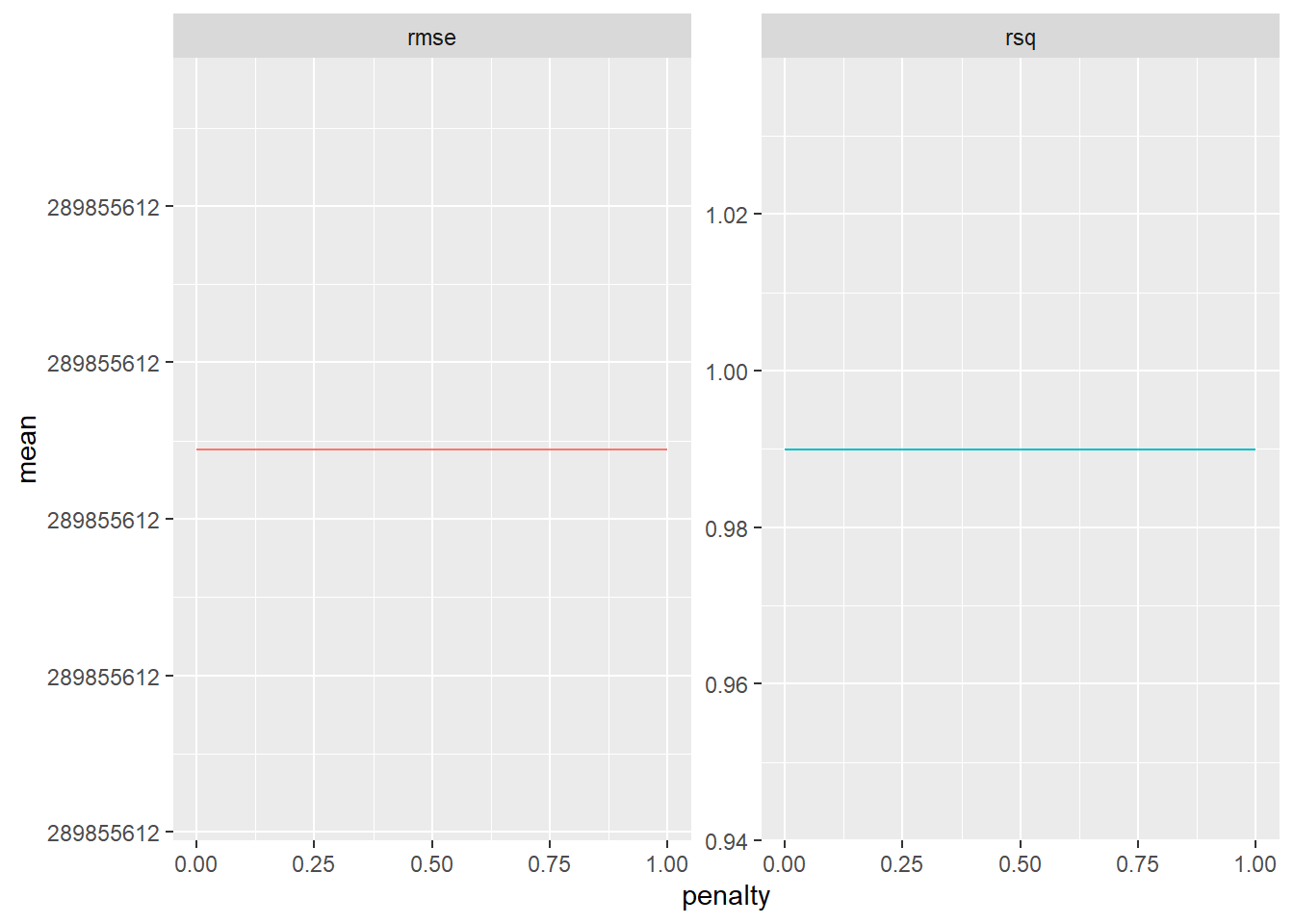
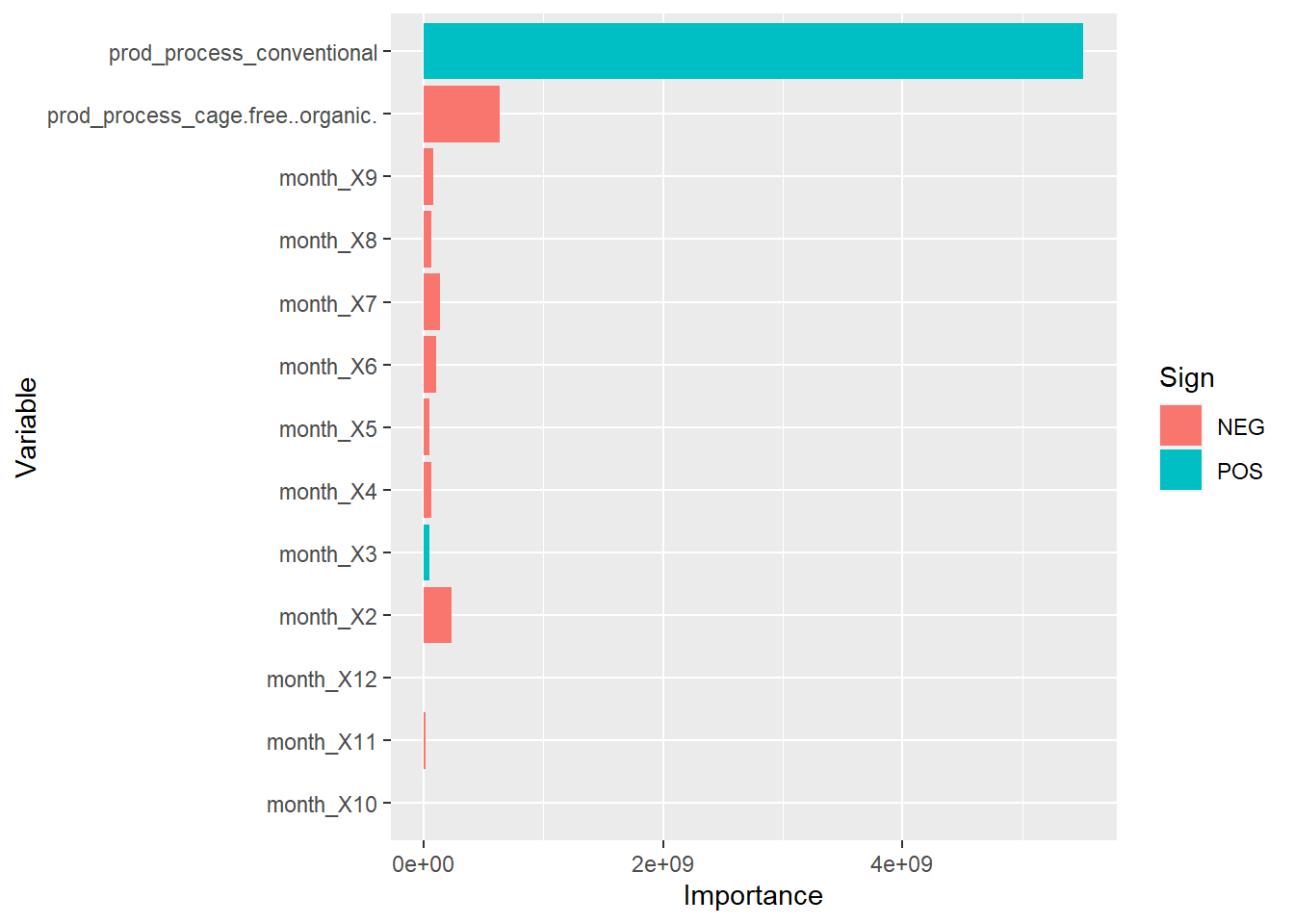
I really liked being able to see the importance of the factors using the graph in the final fit. As predicted, February had a very strong negative effect on egg production, while March actually had a positive impact on egg production - likely a strong bounce-back after the dip in February. I wonder again if the strong impact of production type overshadows the true impact other months have, as I doubt that all months truly have a negative impact on egg production since the general trend of egg production overtime was increased. However, I’m not sure how effective these models actually are since the visual of RMSE/RSQ were straight lines. Again, I don’t know if it’s the model, or how I coded it which actually created the error.
Overall, this exercise helped strengthen my understanding of tidymodels, but I still have a long way to go, especially with tree-based designs and truly comprehending how this framework works to adapt to different data.